![图片[1]-LLM大型语言模型在简历解析和人岗匹配中的应用-JieYingAI捷鹰AI](https://www.jieyingai.com/wp-content/uploads/2024/07/1719774160881_0.png)
引言
在信息时代,数据作为重要资产的价值日益凸显。招聘行业同样如此,从简历解析到候选人匹配,都需要大量的数据处理和分析。近年来,大型语言模型(LLM)如GPT-4、BERT等,在自然语言处理(NLP)领域内产生了革命性的影响。本文将深入探讨LLM在简历解析和人岗匹配中的应用。
LLM简介
大型语言模型(LLM)是通过深度学习技术和大量文本数据训练出来的模型,具有很高的准确度和广泛的应用场景。模型一般是由数十亿甚至数百亿个参数构成的人工神经网络,专门用于理解和生成自然语言文本。这种模型的训练数据通常非常庞大,包含了大量的文本资料,从而使其具有强大的语言理解和生成能力。LLM能够对自然语言进行高度复杂的处理,从而实现文本分类、命名实体识别(NER)、生成文本等多种任务。与传统机器学习模型相比,LLM能更准确地理解语义、语法和上下文,从而在各种NLP任务中表现出色。模型如GPT-4由数百GB甚至TB级别的参数组成,能在多个任务中迁移学习,提供更强的泛化能力。
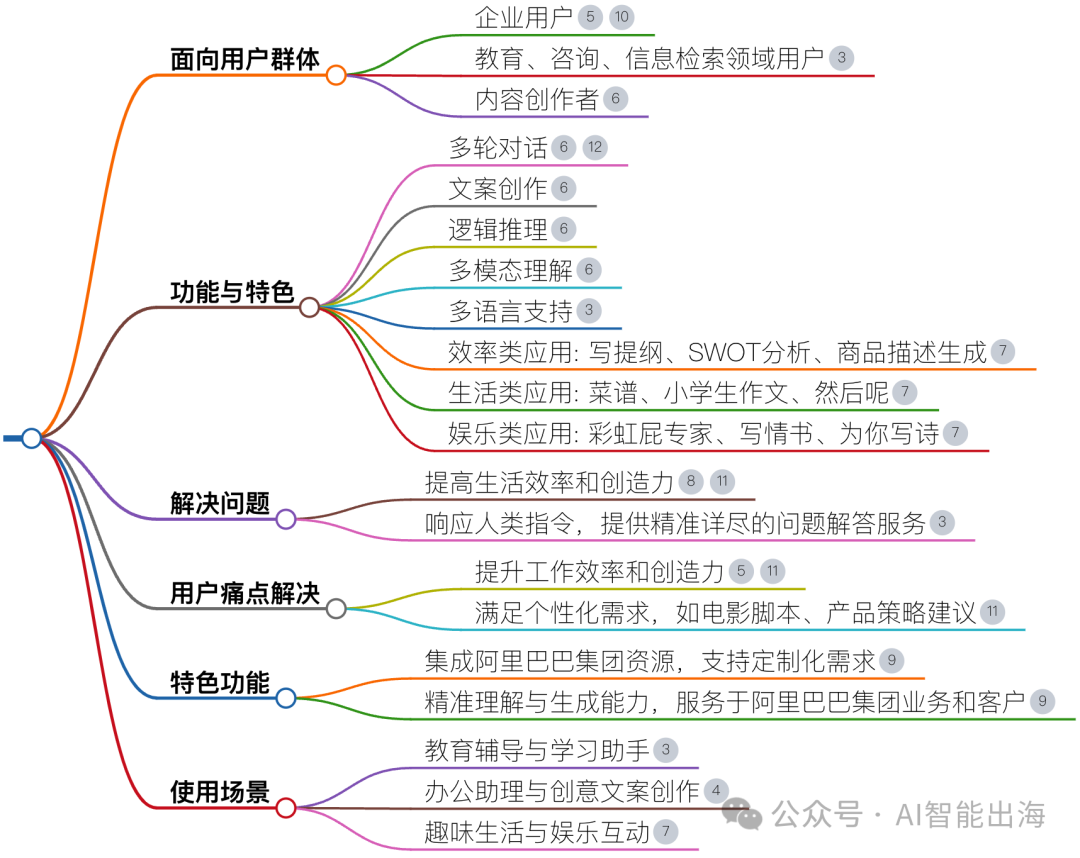
LLM在招聘行业中的使用情况
LLM在招聘行业的应用十分广泛,包括但不局限于如下场景:
本文会结合小析智能产品的应用场景,具体深入探讨简历解析以及人岗匹配方面应用。
![图片[2]-LLM大型语言模型在简历解析和人岗匹配中的应用-JieYingAI捷鹰AI](https://www.jieyingai.com/wp-content/uploads/2024/07/1719774160881_1.png)
在简历解析系统中的具体应用
段落区分
简历通常包含多个区块,在简历解析中,首先需要确定文档的各个部分,例如“个人信息”、“教育经历”、“工作经验”、“技能”等。LLM可以通过识别关键词、语法结构以及上下文内容,进行文本分类来实现这一点。例如,当检测到诸如“大学”、“硕士”等关键词时,模型会标注该段落为“教育背景”。
命名实体识别(NER)
命名实体识别是从文本中识别出具有特定意义的实体,如人名、地名、组织名等。在简历解析中,NER用于识别公司名称、职位、技能、学校等。例如在“2015-2018年,在微软担任软件工程师”的句子中,LLM能够识别“微软”为公司名称、“软件工程师”为职位、“2015-2018”为工作时间。
行业职能分类
通过LLM的文本分类功能,我们可以对候选人以及每段工作经历进行更精细的行业和职能分类。如果一个候选人有多年的软件开发经验和一份与计算机科学相关的学位,LLM可以准确地将此人分类为“IT与软件开发”。相比于传统的机器学习分类算法,LLM可以结合不同的prompt来预测不存在训练数据集中的行业职能类型。
行业技能学校公司知识谱图
LLM通过整合大量文本数据,已能初步覆盖知识图谱的功能。通过分析大量的简历和职位描述,LLM可以构建一个行业-技能-学校-公司的知识图谱。IT行业中,LLM能识别“Python”和“Java”为常见技能,同时将“MIT”和“斯坦福大学”识别为顶级教育机构,甚至在其中找出企业、行业、技能、学校的对应关系。
LLM在人岗匹配上的应用
当有了一个高效的简历解析系统后,下一步就是根据岗位需求在简历库中寻找合适的候选人、以及根据简历内容推荐合适的岗位。LLM同样在这一环节展现了强大的实力。
候选人推荐
在人才招聘过程中,准确地匹配候选人和职位要求是至关重要的一步。传统的筛选方法通常依赖于关键词匹配,但这种方法往往忽略了文本中的语义和上下文信息,导致结果可能并不精确。LLM在这方面表现出显著的优势,它不仅能进行关键词匹配,还能进行深入的语义分析。雇主在发布职位时,通常会有详细的职责描述、技能需求等信息。LLM可以对这些信息进行深度解析,再结合已解析的简历库,智能地进行匹配和排序。这一过程不仅考虑了技能和经验的匹配,还能够考虑到公司文化、求职者的职业倾向等深层次因素。例如,即使简历中没有出现“团队合作”这个词,但如果描述了与团队合作密切相关的经验和成果,LLM也会将其识别为符合职位要求的候选人。
职位推荐
在现代招聘和求职平台上,职位推荐是一个关键的功能,能有效地帮助求职者找到合适的工作机会。传统的推荐系统主要依赖于规则或者简单的算法,但这种方法常常不能完全满足个性化和准确性的需求。LLM在这方面提供了一种更为先进和精准的解决方案。除了对简历和职位描述的直接分析外,LLM还能利用用户行为和历史数据进行更为精准的推荐。例如,如果某个求职者经常浏览和申请软件开发的职位,那么这一行为模式就会被纳入模型的计算中。更进一步,通过分析求职者过去的点击、申请和反馈记录,LLM能自动调整推荐算法,使之更加符合用户的实际需求和兴趣。
![图片[3]-LLM大型语言模型在简历解析和人岗匹配中的应用-JieYingAI捷鹰AI](https://www.jieyingai.com/wp-content/uploads/2024/07/1719774160881_2.jpg)
LLM方法对比
零样本学习(Zero-Shot Learning)
在没有看到特定任务样本的情况下,LLM可以利用其训练期间获得的知识来执行该任务。这被称为“零样本学习”。例如,即使在模型训练数据中没有关于“简历解析”的专门信息,LLM仍然能够理解和执行简历解析任务。这得益于模型在训练过程中已经学习了大量的语言结构和语义信息。
少样本学习(Few-Shot Learning)
在“少样本学习”中,模型会查看一小批与特定任务相关的样本,然后尝试根据这些样本来执行任务。这不仅可以提高模型在该任务上的表现,而且通常也能加速模型的收敛速度。比如,在进行简历解析时,如果提供几个简历样本,LLM会更准确地执行相应的解析任务。通常小样本学习在LLM的环境中可以通过prompt engineering的形式实现。
微调(Fine-Tuning)
尽管零样本学习和少样本学习都是有用的,但在某些高度专业化或特定的任务中,模型可能需要更精确地调整以达到最佳性能。这时,就可以通过“微调”来调整模型的参数。在微调过程中,模型会在特定任务的数据集上进行额外的训练,以优化其在该任务上的表现。这通常会涉及调整模型权重,以便模型更好地适应新任务。
结果对比
利用小析智能内部标注的1万份简历样本数据作为测评的数据集(其中不包含模型训练数据),我们对比了不同LLM模型在各任务的得分。从表格中的结果可以得知通常情况下微调模型的训练结果会优于零样本及少样本的预测结果。在姓名解析的任务中,微调LLM模型甚至可以达到比基于充足训练数据的传统ML模型更好的效果。
![图片[4]-LLM大型语言模型在简历解析和人岗匹配中的应用-JieYingAI捷鹰AI](https://www.jieyingai.com/wp-content/uploads/2024/07/1719774160881_3.png)
结束语
随着LLM技术的不断成熟,其在招聘行业的应用将更加广泛和精细。未来可能会出现更多与LLM结合的招聘工具和服务,大大提升招聘的效率和准确度。LLM在简历解析和人岗匹配方面具有巨大的潜力和应用价值。通过高度自动化和智能化的处理,LLM不仅可以提升招聘团队的工作效率,还可以大幅提高候选人匹配的准确度。在人才市场日益竞争激烈的今天,这无疑是一个重要的竞争优势。
----------
附件
模型
段落区分 (F1)
姓名 (F1)
公司名 (F1)
学校名 (F1)
零样本学习
76.1%
93.7%
87.2%
94.3%
少样本学习
82.5%
96.6%
89.5%
94.6%
微调模型
89.8%
98.9%
95.7%
98.1%
传统ML模型
95.1%
98.8%
97.1%
98.6%